INTRO
안녕하세요. 지난 글에서는 서비스의 규모가 커짐에 따라 더 많은 트래픽을 수용하기 위해 서버를 확장하는 두 가지 방식에 대해서 알아보았습니다. 각각 방식에 장단점이 존재하기 때문에 개발 중인 서비스의 특징에 맞게 선택할 필요가 있었고, Hello-World는 서비스의 특징을 봤을 때 서비스의 지속성을 유지하는 것이 더 중요하므로 이에 대해 우위가 있는 Scale out을 선택하기로 결정하였습니다.
하지만 Scale out을 선택했을 때 고려해야할 부분은 역시나 데이터의 불일치 문제입니다. 여러 서버가 각각의 메모리 저장 공간을 가지고 있는데, 세션(Session)을 활용한 로그인을 사용할 경우 세션의 특성상 각 서버간에 공유가 되지 않기 때문입니다. 본 글에서는 이러한 문제점을 좀 더 자세히 살펴보고 이를 어떤 방식으로 해결할 수 있을 지 알아보도록 하겠습니다.
다중 서버환경에서 세션 로그인 방식이 가지는 ISSUE
위에서 잠깐 언급했지만, Scale out 방식으로 확장된 서버의 경우에는 다수의 서버가 함께 운영되며, 각각의 서버가 세션을 보관하기 위한 저장소를 따로 가지고 있습니다. 사용자가 처음 로그인을 할 경우 요청을 받은 서버는 해당 정보를 세션에 담아 자신의 저장소에 저장한 뒤 사용자에게는 쿠키(Cookie)를 통해 세션 ID를 전달해줍니다. 이후 사용자 쪽에서 요청을 보낼 때 서버가 부여한 세션 ID를 함께 전달하게 되고, 서버 측에서는 해당 ID를 가지고 저장해 둔 값을 찾아 사용자의 로그인 여부를 확인합니다. 이러한 구조 덕분에 사용자는 로그아웃을 하거나 세션이 만료되어 해당 세션 정보가 서버에서 사라지기 전까지는 다시 로그인을 할 필요가 없이 서비스를 이용할 수 있게 되는 것입니다.

하지만 각각 서버의 저장소에 저장된 세션 정보는 고유하며, 다른 서버간 공유되지 않는다는 부분에서 문제가 시작됩니다. Scale out 방식으로 확장된 다중 서버는 트래픽의 효율적인 분산을 위해 서비스를 운영 할 때 로드 밸런싱(load balancing) 기술이 필수적으로 적용됩니다. 이때 트래픽의 분산을 담당하는 로드 밸런서(load balancer)는 기본적으로 트래픽 분산 알고리즘을 활용해 트래픽이 집중되지 않은 서버에 트래픽을 전달하기 때문에 A, B, C 세 개의 서버가 운영된다고 했을 때, 사용자가 처음 로그인 해서 세션 정보가 저장된 서버가 A라고 하더라도 다음 요청을 보낼 때는 해당 요청이 꼭 똑같은 서버로 전달된다는 보장이 없습니다. 그래서 사용자가 방금 막 로그인을 했다고 하더라도 해당 로그인 정보가 다른 서버에는 존재하지 않게되는 데이터 불일치의 상황이 발생하게 됩니다.
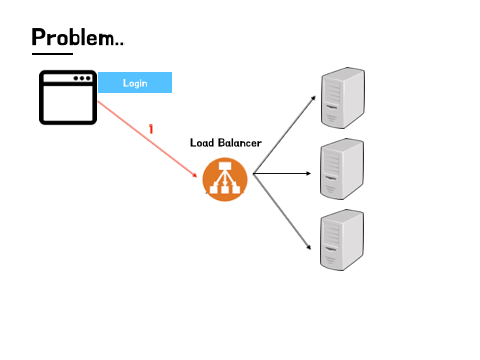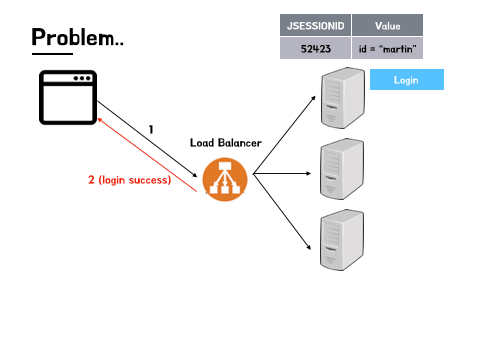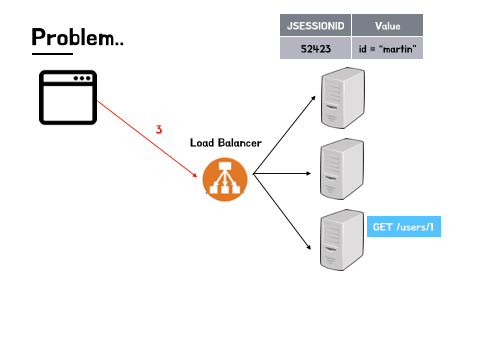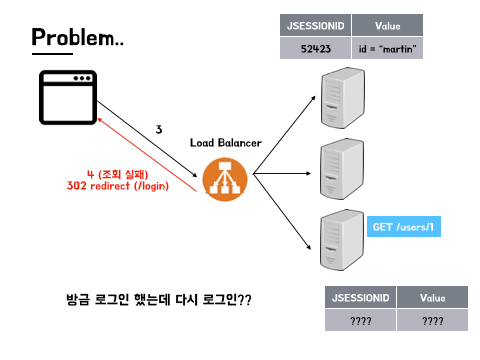
이러한 문제가 계속 발생한다면 서비스를 이용하는 사용자들이 꽤나 큰 불편을 겪게 될 것입니다. 페이지를 이동할 때마다 서버에서 재 로그인을 요구한다면 비밀번호가 복잡할수록, 그리고 더 나은 보안을 위해 추가적인 인증방식을 더 많이 활용하고 있을 수록 그 불편은 배가 될 것입니다. 서버 입장에서도 자원낭비 문제가 발생할 수 있겠습니다. 사용자들의 요청이 매번 다른 서버로 간다면 다시 로그인을 해야할 것이고 결국 각 서버에 같은 세션 데이터가 계속해서 따로 쌓이는 상황에 이르게 될 것입니다. 이렇게 사용자와 서버 모두 손해를 입는 상황을 청산하기 위해서는 세션 불일치의 문제를 해결할 필요가 있겠습니다.
세션 불일치를 해결하기 위한 방법으로는 무엇이 있을까요?
1) Sticky Session
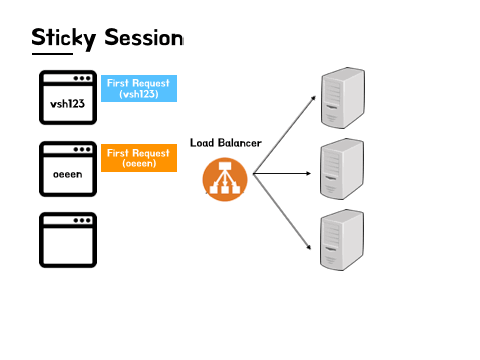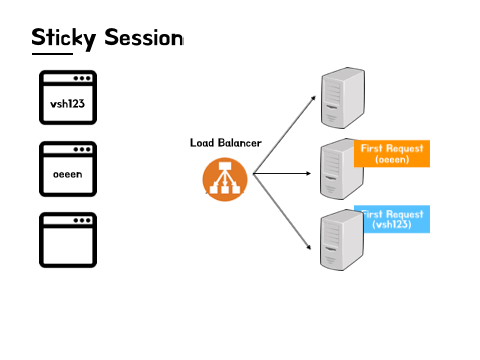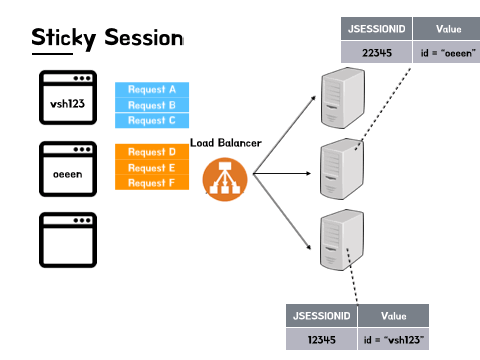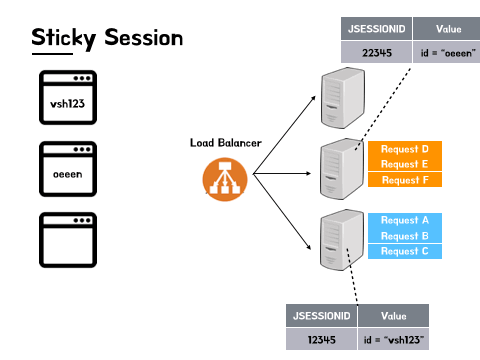
Sticky Session이 갖는 의미는 어딘가에 붙어있다는 'Sticky'라는 단어가 의미하는 것처럼 해당 사용자의 세션정보가 존재하는 서버에 고정적으로 트래픽을 보내는 방식을 의미합니다. 첫 요청은 로드 밸런싱 알고리즘에 의해서 무작위의 서버로 전달이 되지만 한 서버 내에 세션이 생성된 이후에는 그 세션이 만료될 때까지 해당 서버로만 요청을 지속적으로 보내는 것 입니다.
이때 함께 활용되는 것이 위에서 등장했던 쿠키입니다. 사용자의 요청이 동일한 서버로 계속해서 전달될 수 있도록 서버에서 응답을 받을 때 쿠키 안에 서버 정보가 함께 담겨서 전달되고, 다시 사용자가 요청을 보낼 때 로드 밸런서는 쿠키 내의 서버정보를 바탕으로 동일한 서버에 매번 요청을 전달해 데이터의 정합성 이슈를 해결하는 것입니다.
하지만 Sticky Session을 활용했을 때 다음과 같은 문제점이 발생할 수 있습니다. 먼저, 특정 서버에 트래픽이 집중될 수 있다는 점입니다. 로드 밸런서가 적절하게 트래픽을 분산해서 각 서버로 보냈다고 해도 한 서버는 모든 사용자들이 활발하게 서비스를 이용하는 반면에 다른 한 서버에서는 사용자들이 로그인만 한 뒤 서비스를 이용하지 않을 수도 있습니다. 이 경우에 이용률이 낮은 서버 쪽으로 트래픽을 분산시키는 것이 정답이겠으나, 로드 밸런서는 세션이 보관된 서버로만 요청을 보내도록 설정이 되어있으므로 최악의 상황에는 결국 한 서버에만 요청이 집중되어 해당 서버에 과부하가 발생할 수도 있습니다.
다음으로는 특정 서버에 문제가 생길 시 저장되어 있는 세션 정보가 통째로 소실될 수 있다는 부분입니다. 서버를 운영하면서 예기치 못한 상황은 언제든지 벌어질 수 있습니다. 물론 해당 상황이 벌어지기 전에 막을 수 있는 것이 베스트겠지만 에러가 발생할 경우 이에 얼마나 신속하게 대처할 수 있는지도 중요합니다. 하지만 Sticky Session의 경우에는 각 서버마다 고유한 세션 정보를 가지고 있으므로 서버에 문제가 발생하여 해당 서버가 이용 불가능하거나 세션이 모두 사라지는 경우 해결책을 적용하기 이전인 데이터 정합성 이슈가 발생하는 상황으로 다시 회귀하게 될 수 있습니다.
2) Session Clustering (세션 클러스터링)
세션 클러스터링이란 여러 서버 인스턴스의 세션을 묶어서 하나의 클러스터로 관리하는 것을 말합니다. 때문에 여러 서버가 동일한 세션 정보를 공유하고 있고, 로드 밸런서가 트래픽을 세션을 공유하고 있는 어떠한 서버로 보내더라도 세션 불일치의 문제가 생기지 않으므로 데이터 정합성의 이슈가 사라지게 됩니다.
세션 클러스터링 방식이 갖고 있는 가장 큰 장점은 Fail Over가 가능하다는 부분입니다. 혹시나 한 서버에 문제가 생겨 제대로 된 동작이 불가능하더라도 해당 서버의 세션 정보를 다른 서버와 공유하고 있는 상태이므로, 로드 밸런서가 요청을 그 서버들로 보내기만 한다면 클라이언트의 입장에서는 큰 문제 없이 서비스의 이용을 계속 이어나갈 수 있게 됩니다.
Tomcat 공식문서를 보면 All-To-All 방식을 통해 세션 클러스터링을 구현하는 것을 이야기 하고 있습니다.
By all-to-all, we mean that every session gets replicated to all the other nodes in the cluster.

클러스터 내의 모든 노드에 세션을 전부 복제한다는 의미로, 세션 저장소에 변경 요소가 발생할 시 Delta Manager가 이를 관리하며, 변경된 내용을 클러스터 내의 다른 세션 저장소에도 복제하여 반영하는 식으로 동작합니다.
그러나 공식문서에서도 언급되어 있지만 Delta Manager를 활용한 세션 클러스터링 방식은 서버 3대 이상으로 클러스터의 규모가 적은 경우에만 추천하며 서버가 4대 이상인 대규모 클러스터에는 권장하지 않는 방식이라고 적혀 있습니다. 각 서버가 클러스터 내의 모든 세션을 가지고 있기 때문에 서버의 개수가 많아질수록 그만큼 저장하는 세션의 개수가 많아지게 되고, 결국 모든 서버에서 메모리가 부족하게 되는 현상이 나타날 수 있기 때문입니다. 이밖에도 Delta Mange는 모든 세션을 모든 서버의 노드로 복제하기 때문에 애플리케이션을 운영하지 않고 있는 노드에도 세션을 복제해버리는 문제점을 지니고 있습니다.
Delta Manager의 이러한 단점을 보완하기 위해 사용되는 것이 Backup Manager 입니다.
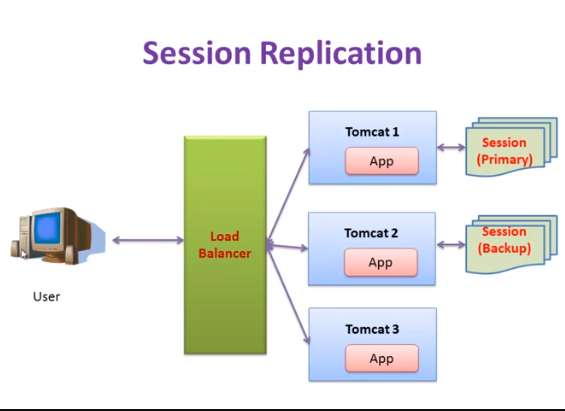
이 방식을 활용하면 세션 저장소가 Primary - Secondary(Back Up)의 구조로 하나의 클러스터로 묶이게 되며, Primary 서버에 대한 모든 세션 정보가 단 하나의 Secondary 서버에 저장이 됩니다. 그리고 해당 클러스터에 해당하지 않는 다른 서버 노드에 대해서는 JSESSION ID만을 복제해 둠으로써 Delta Manager 방식을 활용했을 때보다 메모리 활용에 있어 이점을 갖게되는 구조입니다.
그러나 문제는 사용자가 늘어나면서 여전히 세션 데이터 양의 자체가 여러 서버에서 함께 늘어나게 된다는 부분과 이를 복제하고 전달하는 과정에서 오버헤드가 발생할 수 있다는 단점이 있습니다. 추가로, JSession ID만을 가지고 있는 서버의 경우에는 결국 해당 세션에 대한 값을 불러오기 위해서 이를 보관하고 있는 서버에 요청을 보내야하기 때문에 추가로 트래픽도 발생할 수 있다는 부분과 새로운 서버를 추가할 때마다 일일이 수동으로 해당 서버의 IP/Port를 입력해서 클러스터링 해줘야 하기 때문에, 휴먼 에러가 발생할 가능성도 있다는 점을 배제할 수 없겠습니다.
3) Remote Session Storage (세션 스토리지의 분리)
세션 불일치 문제를 해결하기 위해 마지막으로 고려해볼 방법은 세션을 저장하는 저장소를 별도로 두어 관리하는 것입니다. 즉, 기존 서버들이 갖고 있던 각각의 로컬 세션 저장소 대신 아래와 같이 별도의 공동 세션 저장소를 활용하는 것인데요.

분리된 공동 세션 저장소를 사용하면 모든 세션이 한 저장소로 모이기 때문에 데이터의 정합성에 대한 이슈를 해결할 수 있으며 한 서버에서 장애가 발생하더라도 문제 없이 서비스를 계속 제공할 수 있다는 장점이 있습니다. 또, 새로운 서버를 추가할때 별도의 작업과정을 줄일 수 있습니다. 단순히 새 서버를 세션 저장소에 연결해주기만 하면 되기 때문입니다. 그래서 서버의 증축이나 감축과정을 효율적으로 변화시킬 수 있습니다. 또한 Sticky Session을 사용했을 때 발생할 수 있는 트래픽이 집중현상이나 세션 클러스터링 방식을 활용했을 때 발생할 수 있는 서버 메모리의 비효율적인 사용을 줄일 수 있게 됩니다.
하지만 그만큼 해당 세션 저장소에 대한 의존도가 높아진만큼 이곳에 문제가 생겼을 때 서비스 제공에 차질이 생길 수 있다는 점과 원격으로 해당 저장소에 세션을 저장하고 이를 확인하기 접근할 때 발생할 수 있는 네트워크 비용이나 직렬화/역직렬화에 대한 비용 또한 간과해서는 안될 부분일 것입니다.
결론
서비스의 규모가 커질 수록 서버의 자원을 효율적으로 사용하는 부분이나 들어오는 트래픽을 관리하는 부분이 꽤나 중요하게 작용할 것이라 생각했으며, 세션 저장소의 경우는 비영속성의 특징을 가진 세션의 성격이나 솔루션에 따라 세션 저장소 자체를 다시금 복제해서 둘 수 있다는 점을 고려하여 현재 진행하고 있는 프로젝트인 Hello-World에서는 별도의 세션 저장소를 활용하기로 결정하였습니다.
OUTRO
지금까지 Scale Out 방식을 활용했을 때 발생할 수 있는 데이터 불일치 문제에 대한 세 가지 해결책을 살펴보았습니다. 다음 글에서는 이번 글의 선택(세션 스토리지의 분리)을 바탕으로 이를 구현할 때 고려할 점을 알아보고 이를 통해 어떤 솔루션을 선택했는지 알아보도록 하겠습니다.
References
smjeon.dev/web/sticky-session/
tomcat.apache.org/tomcat-9.0-doc/cluster-howto.html
Project
github.com/f-lab-edu/Hello-World
f-lab-edu/Hello-World
언어교환 상대찾기 서비스. Contribute to f-lab-edu/Hello-World development by creating an account on GitHub.
github.com



