안녕하세요. 저번시간에는 성능 테스트의 필요성을 알아보고 성능을 측정하는데 있어 대표적인 기준이 될만한 지표들에 대해서 살펴본 뒤 성능 테스트 시 사용할 도구들을 직접 설치해봄으로써 배포한 서버를 대상으로 한 성능 테스트를 진행하기 전 사전 작업을 완료하였습니다. 이제 테스트를 구동할 준비를 모두 마쳤으니 이번 시간에는 nGrinder를 사용해 타겟 서버에 직접 부하를 가해보면서 테스트가 진행되는 동안 pinpoint와 Jvisualvm 등의 도구를 통해 해당 서버가 부하 속에서도 제대로 동작하고 있는지 모니터링 해보는 시간을 갖도록 하겠습니다.
시작하기에 앞서 성능 테스트를 진행한 서버의 사양과 구조는 다음과 같습니다.
서버 사양
- 애플리케이션 서버 - CPU: 2코어, RAM: 4GB
- DB 서버 - CPU: 2코어, RAM: 2GB(Master, Slave 서버 모두)
- Redis 서버 - CPU: 2코어, RAM: 4GB(Session, Cache 서버 모두)
서버 구조

서버의 확장이 용이하도록 이미 Session 데이터를 레디스에 저장하게 만들어 뒀기 때문에, 필요한 경우는 언제든지 서버를 추가로 구성할 수 있습니다. (캐시 또한 글로벌 저장소를 사용하기 때문에 마찬가지 입니다.) 이때, 사용자로부터 들어온 요청이 각 서버에 고르게 분산되도록 로드밸런싱 하기 위해 사이에 Nginx를 두었습니다.
서버의 사양과 구조를 살펴봤으니 본격적으로 성능테스트를 진행해보도록 할텐데요. 구성요소들이 모두 Cloud 서버 상에 존재하며, 예산의 제한이 있기 때문에 처음에는 WAS 한 대를 가지고 성능 테스트를 진행하고, 부하로 인해 해당 서버 처리 성능에 한계가 찾아오면 서버를 확장하는 식으로 테스트를 구성해보도록 하겠습니다. 그럼 먼저 테스트에 활용할 스크립트를 작성해보겠습니다.
성능테스트 스크립트 작성하기
nGrinder는 성능테스트 시 스크립트를 만들어 테스트할 수 있는 기능을 지원합니다. 스크립트를 작성하는데 사용할 수 있는 언어로는 몇 가지가 있었는데, 저는 자바가 제일 익숙했으므로 Groovy를 사용해서 테스트를 작성했습니다. nGrinder Controller 웹페이지에서 스크립트 작성하기를 누르면 예시가 있고, 이를 활용해 본인이 테스트 할 내용에 맞게 스크립트를 작성하면 됩니다. 혹시 모르니 여기서는 예시로 제가 테스트 시 사용했던 스크립트를 함께 첨부하도록 하겠습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
|
import static net.grinder.script.Grinder.grinder
import static org.junit.Assert.*
import static org.hamcrest.Matchers.*
import net.grinder.plugin.http.HTTPRequest
import net.grinder.plugin.http.HTTPPluginControl
import net.grinder.script.GTest
import net.grinder.script.Grinder
import net.grinder.scriptengine.groovy.junit.GrinderRunner
import net.grinder.scriptengine.groovy.junit.annotation.BeforeProcess
import net.grinder.scriptengine.groovy.junit.annotation.BeforeThread
// import static net.grinder.util.GrinderUtils.* // You can use this if you're using nGrinder after 3.2.3
import org.junit.Before
import org.junit.BeforeClass
import org.junit.Test
import org.junit.runner.RunWith
import java.util.Date
import java.util.List
import java.util.ArrayList
import HTTPClient.Cookie
import HTTPClient.CookieModule
import HTTPClient.HTTPResponse
import HTTPClient.NVPair
import groovy.json.JsonOutput
/**
* A simple example using the HTTP plugin that shows the retrieval of a
* single page via HTTP.
*
* This script is automatically generated by ngrinder.
*
* @author admin
*/
@RunWith(GrinderRunner)
class TestRunner {
public static GTest test
public static HTTPRequest request
public static NVPair[] headers = []
public static Cookie[] cookies = []
@BeforeProcess
public static void beforeProcess() {
HTTPPluginControl.getConnectionDefaults().timeout = 6000
test = new GTest(1, "{your ip or host address}")
request = new HTTPRequest()
test.record(request)
List<NVPair> headerList = new ArrayList<>()
headerList.add(new NVPair("Content-Type", "application/json"))
headers = headerList.toArray()
}
@BeforeThread
public void beforeThread() {
grinder.statistics.delayReports=true;
def threadContext = HTTPPluginControl.getThreadHTTPClientContext()
cookies = CookieModule.listAllCookies(threadContext)
cookies.each {
CookieModule.removeCookie(it, threadContext)
}
def reqBody = JsonOutput.toJson([userId: 'msugo1', password: '!@345Gomsu'])
HTTPResponse result = request.POST("http://{your ip or host address}:{port}/{endpoint}", reqBody.getBytes(), headers);
cookies = CookieModule.listAllCookies(threadContext)
}
@Before
public void before() {
request.setHeaders(headers)
cookies.each {
CookieModule.addCookie(it, HTTPPluginControl.getThreadHTTPClientContext())
}
}
@Test
public void getUserProfiles() {
HTTPResponse result = request.GET("http://{your ip or host address}:{port}/{endpoint}");
if (result.statusCode == 301 || result.statusCode == 302) {
grinder.logger.warn("Warning. The response may not be correct. The response code was {}.", result.statusCode);
} else {
assertThat(result.statusCode, is(200));
}
}
@Test
public void searchUserProfiles(){
def levels = ['ADVANCED']
def reqBody = JsonOutput.toJson([speakLanguage: 14, learningLanguage: 2, learningLanguageLevel: levels])
HTTPResponse result = request.POST("http://{your ip or host address}:{port}/{endpoint}", reqBody.getBytes());
if (result.statusCode == 301 || result.statusCode == 302) {
grinder.logger.warn("Warning. The response may not be correct. The response code was {}.", result.statusCode);
} else {
assertThat(result.statusCode, is(200));
}
}
@Test
public void getOneUserProfile() {
HTTPResponse result = request.GET("http://{your ip or host address}:{port}/{endpoint}");
if (result.statusCode == 301 || result.statusCode == 302) {
grinder.logger.warn("Warning. The response may not be correct. The response code was {}.", result.statusCode);
} else {
assertThat(result.statusCode, is(200));
}
}
}
|
c |
테스트를 시작하기에 앞서, 현재 프로필 조회 기능 사용 시 성능 개선을 위해 소스코드에는 이미 캐싱이 적용되어 있는 상태입니다. 하지만 캐싱 적용 후 얼마만큼의 차이가 있는지 확인해보는 것도 의미가 있을 것이라 생각했고, 아래 처럼 캐싱 관련 부분을 주석처리하여 서버에 어플리케이션을 재배포하였습니다.
@Transactional(readOnly = true)
// @Caching(cacheable = {
// @Cacheable(key = MAIN_PAGE_KEY, value = MAIN_PAGE_VALUE, condition = "#pagination.cursor == null", cacheManager = REDIS_CACHE_MANAGER),
// @Cacheable(key = "#pagination.cursor", value = USER_PROFILES, condition = "#pagination.cursor != null", cacheManager = REDIS_CACHE_MANAGER)
// })
public List<UserProfiles> getUserProfiles(String userId, Pagination pagination) {
return profileMapper.getUserProfiles(userId, pagination);
}
@Transactional(readOnly = true)
public List<UserProfiles> searchUserProfiles(SearchConditionsRequest conditionsRequest, String userId, Pagination pagination) {
Set<LanguageLevel> learningLangLevels = conditionsRequest.getLearningLanguageLevel();
LanguageLevelValidator.validateLevel(learningLangLevels, LanguageStatus.LEARNING);
SearchConditions conditions = SearchConditions.create(conditionsRequest, userId, pagination);
return profileMapper.searchUserProfiles(conditions);
}
자! 그럼 테스트를 위한 모든 준비가 완료되었으니 nGrinder를 작동시켜 구동시켜 놓은 어플리케이션 서버에 부하를 가해보겠습니다.
1차 성능 테스트 - Vuser 500명, 테스트 시간 10분
처음부터 한 번에 많은 부하를 줘서 테스트하기보다는 점진적인 방식으로 테스트하는 것을 선택하였습니다. 그래서 처음에는 500명 정도로 테스트해보고 문제가 있는지 살펴본 뒤 문제가 없을 시 부하를 더 증가시키는 방식을 채택하였습니다. 또한 테스트의 신뢰도를 높이기 위해서 지속 시간은 10분 정도로 설정 해주었습니다.
nGrinder 설정

테스트 초기 각 서버의 자원 사용률
1) WAS 서버

2) MySQL 서버

애플리케이션 서버의 CPU 사용량은 모든 코어가 100%에 달하고 있으며, MySQL 서버의 경우는 애플리케이션 서버의 부하에도 불구하고 CPU 사용량이 20~30% 대로 높지 않아서 양 서버 간 CPU 사용량이 꽤나 이상적인 모습을 띄고 있습니다. 하지만 성능 테스트를 시작한 지 몇 분이 채 지나지 않아 문제가 발생하기 시작했습니다.
약 5분 정도 경과 후 각 서버의 자원 사용률
1) WAS 서버

2) MySQL 서버

애플리케이션 서버의 CPU 사용률이 급격히 줄어들기 시작하더니, 반대로 DB 서버의 CPU 사용률은 급격히 증가하기 시작합니다. 이에 상응하는 효과로 TPS 또한 급격히 감소하는 모습을 보여주었습니다.
1차 성능테스트 결과
1) nGrinder 결과
각 서버의 사양을 고려해 보면 500명의 부하는 거뜬히 처리해야 합니다. 그럼에도 CPU 사용률이 급격히 저하되는 문제가 있었고, 이와 더불어 상당히 높은 에러 수, 그리고 낮고 불안정한 TPS라는 여러 문제점이 확인되었습니다.


2) pinpoint 결과
앞선 포스팅에서는 성능테스트 시 발생하는 다양한 문제의 원인을 찾아내기 위해서 APM 도구인 핀포인트를 설치해 두었는데요. 테스트를 마치고 꽤나 많은 문제가 확인되어 핀포인트를 살펴보니 꽤나 심난했습니다. 먼저 실시간 응답속도 그래프입니다. 요청을 처리하는데 최대 4~5초까지도 걸리는 모습을 볼 수 있었습니다. 이는 서비스 사용자들이 큰 불편함을 느낄 수 있는 수치임과 함께 서버의 처리 성능 또한 문제가 있다는 반증이므로 해결이 꼭 필요했습니다.


원인 분석
문제점을 찾아내기 위해서 핀포인트가 제공해주는 트랜잭션 처리 Call Tree를 자세히 살펴보았습니다. 그리고 로그인 API를 호출하는 과정에서 DB 커넥션을 얻어오는 getConnection을 처리하느라 많은 시간이 걸림을 알 수 있었습니다.
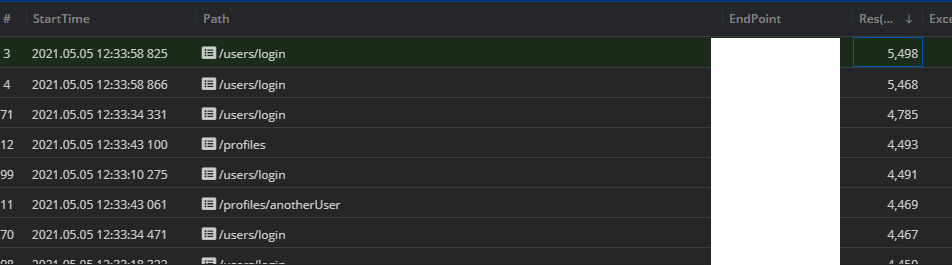

getConnection( )?
getConnection이란 말 그대로 커넥션을 얻어오는 역할을 하는 메소드입니다. 여기서 말하는 커넥션이란 WAS 서버와 DB 서버 간의 커넥션을 의미합니다. 두 서버간의 통신을 위해서는 커넥션이 필요한데, 커넥션을 생성하는데는 많은 비용이 소모가 됩니다. (이 부분은 다음 포스팅에서 더 자세히 알아보겠습니다.) 때문에 매번 커넥션을 생성하는 것이 아니라 Connection Pool이라는 것을 만들어 미리 생성한 커넥션을 저장해두고 getConnection요청이 들어오면 해당 풀에서 커넥션을 가져다 쓰는 방식이 사용됩니다. 그런데 이때 커넥션 풀에 남는 커넥션이 없다면, 요청을 보낸 쓰레드는 남는 커넥션이 반환될 때까지 기다리게 됩니다.
실제로 핀포인트 Inspector가 제공해주는 그래프를 살펴보니 테스트가 수행되는 대부분의 시간 동안 주어진 커넥션이 모두 사용되고 있음을 확인할 수 있었습니다.

일단 지금까지의 지표는 문제의 원인이 데이터베이스 쪽, 그것도 커넥션과 관련해서 발생했음을 가리키고 있는데요. 사실, 커넥션 풀 내부의 커넥션 개수 또한 따로 설정해주지 않고 기본 값으로 첫 테스트를 진행했습니다. 다음 포스팅에서는 문제 해결의 실마리일 가능성이 있는 DB Connection에 대해 좀 더 자세히 알아보고, 필요한 설정들을 조정한 뒤 다시 테스트를 진행해서 경과를 살펴보는 시간을 갖도록 하겠습니다!
프로젝트 링크
https://github.com/f-lab-edu/Hello-World
f-lab-edu/Hello-World
언어교환 상대찾기 서비스. Contribute to f-lab-edu/Hello-World development by creating an account on GitHub.
github.com
'Project > Hello-World (Language Exchange)' 카테고리의 다른 글
| 배포 서버를 대상으로 한 성능테스트 및 성능개선 (4) - 문제의 진짜 원인을 찾아서 (feat. 슬로우 쿼리 & BCrypt) (0) | 2021.06.09 |
|---|---|
| 배포 서버를 대상으로 한 성능테스트 및 성능개선 (3) - DB Connection (0) | 2021.06.05 |
| 배포서버 성능테스트 및 성능개선 (1) - 성능테스트의 필요성을 살펴보고, 필요한 환경을 구성해 봅시다. (0) | 2021.04.27 |
| 대용량 트래픽 속에서도 무거운 DB 조회 연산을 효율적으로 처리하는 방법은 무엇이 있을까요? (2) (0) | 2021.04.13 |
| 대용량 트래픽 속에서도 무거운 DB 조회 연산을 효율적으로 처리하는 방법은 무엇이 있을까요? (1) (0) | 2021.03.29 |



