안녕하세요. 저번 시간에는 nGrinder를 활용해 직접 성능테스트를 실행하고, 이를 pinpoint 등의 도구를 사용해서 모니터링을 해보는 시간을 가졌습니다. 그리고 원인은 확실하지 않지만 문제가 있는 부분도 찾아낼 수 있었는데요. 오늘은 해당 문제 해결의 실마리가 될 수도 있는 DB Connection에 대해 좀 더 살펴보고, 해당 내용을 실제로 적용한 뒤 테스트를 다시 진행해봄으로써 실제로 커넥션이 문제를 유발하고 있었는지 살펴보도록 하겠습니다. 먼저, 본론에 들어가기에 앞서 커넥션이 무엇인지부터 시작하겠습니다.
DB connection이란?
커넥션은 이름이 의미하는 바와 같이 연결과 관련이 있습니다. 한 개체가 다른 서버 상에 존재하는 개체와 통신하기 위해서는 이를 뒷받침 할 수단이 필요한데, 이때 사용되는 것이 바로 커넥션입니다. DB 커넥션은 말 그대로 데이터 베이스와의 통신을 위해 사용되는 커넥션을 의미합니다. 여기서 해당 커넥션을 사용하는 주체는 바로 애플리케이션 서버(WAS)가 되겠습니다.
특별한 설정이 없다면 WAS 서버가 CRUD 작업을 위해 데이터베이스에 요청을 보낼 때 DB 커넥션이 하나씩 생성이 되고, 작업을 마치면 해당 커넥션이 소멸되는 것이 기본적인 동작방식입니다. 이때 커넥션을 맺는 서버 간의 데이터 송수신을 완벽히 보장하기 위해서 TCP 프로토콜을 사용하는데 TCP 특유의 준비과정으로 인해 꽤나 큰 부하가 발생하게 됩니다. 이를 좀 더 자세히 살펴보면 다음과 같습니다.

여기서 위는 커넥션을 맺기까지의 과정이고, 아래는 작업을 모두 마친 후 커넥션을 종료하는 과정입니다. 온전한 커넥션의 확립을 위해서 양 서버가 적어도 3번의 패킷을 주고 받고 나서야 제대로 된 커넥션이 만들어지며, 커넥션을 제거할 때는 적어도 4번의 패킷 교환이 이루어져야 이러한 과정이 마무리되기 때문에 각각 3-way handshaking , 4-way handshaking이라고 부르기도 합니다.
이렇게 복잡한 과정을 거치고 나서야 제대로 된 통신이 이루어지기 때문에 각 요청당 커넥션을 하나씩 만들게 되면, 서버로 들어오는 트래픽이 많아질수록 요청 처리시 드는 비용은 기하급수적으로 증가하고 이로 인해 성능에도 큰 악영향을 미치게 됩니다. 실제로 MySQL의 공식문서를 보면 다음과 같이 DB 서버로 쿼리를 하나 날렸을 때의 비용이 다음과 같이 정리되어 있습니다.

Connection Pool 방식의 활용
위에서 살펴본 것처럼 커넥션을 맺고 끝는 과정에서 소모되는 비용이 실제로 쿼리를 파싱하고, 처리하는 것보다 더 많은 비용을 차지합니다. 그래서 이러한 문제점을 해결하고자 등장한 것이 Connection Pool 방식입니다. 이전처럼 개별 요청마다 커넥션을 생성하고 제거하는 대신에 커넥션을 미리 생성해서 이를 Pool에 담아 놓은 다음, 커넥션이 필요할 때마다 꺼내서 재사용하게 됩니다. 미리 만들어진 커넥션을 사용하므로 3-way handshaking 과정을 거치지 않게 되므로 부하가 줄어들어 성능이 향상될 뿐만 아니라, 더 빠른 통신도 가능해집니다.
DB Connection Pool 동작 방식

1) Connection 요청하기
클라이언트로부터 받은 요청을 처리하는 쓰레드가 DB에 접근해야 하는 경우가 생기면 커넥션 풀에 커넥션을 요청하게 됩니다. 이때, 커넥션 풀 구현체에 따라 커넥션을 넘겨주는 방식이 조금 다른데요. 현재 스프링 부트에서 사용하는 HikariCP의 경우에는 이전에 사용했던 커넥션에 대한 정보를 관리하고 요청을 보낸 쓰레드가 이전에 사용했던 커넥션이 대기중이라면 이를 우선적으로 반환합니다. 만약 해당 커넥션이 이미 사용중이라면 다른 대기중인 커넥션을 찾아서 반납하게 되고, 모든 커넥션이 사용 중이라면 커넥션을 요청한 쓰레드는 HandOffQueue로 가서 이용가능한 커넥션이 생길 때까지 대기하고, 정해진 Timeout 시간을 초과해도 남는 커넥션이 생기지 않는 경우는 타임아웃 예외를 발생시키게 됩니다.

2) Connection 반납하기
커넥션을 가져간 쓰레드가 사용을 모두 마치면 commit/rollback 여부에 관계 없이 close( )메소드를 호출하고, 이를 통해 다시 커넥션 풀에 커넥션을 반환합니다. 이때, 사용한 커넥션에 대한 정보를 등록하고 이는 차후에 커넥션을 재 요청할 때 활용됩니다.
적절한 커넥션 풀 개수 찾기
이전 포스팅에서 성능테스트 시 pinpoint를 통해 성능 저하를 유발하는 원인이 될 수도 있는 부분이 바로 커넥션 풀에서 커넥션을 얻어오는 지점임을 확인할 수 있었습니다. 위에서 Connection Pool이 작동하는 작동 방식에 대해서 알아보았기 때문에 이제는 getConnection 메소드 수행 시간이 길다는 의미가 커넥션의 부족 현상이라고 말할 수 있습니다. 아마 부하 수가 vUser 500이었기 때문에, 커넥션 10개로 처리하기에는 역부족이었나 봅니다.
스프링 부트의 경우 application.properties 혹은 application.yml에서 'spring.datasource.master.maximum-pool-size' 설정 값을 수정하면 간단하게 커넥션 풀의 개수를 늘려줄 수 있습니다. 주의할 점은 Replication을 통해 두 개 이상의 DB를 사용하는 경우 아래와 같이 Datasource 설정에 사용하는 prefix를 명시하고 그 뒤에 maximum-pool-size를 붙여야 한다는 점입니다. 저는 처음 설정할 때 그 사실을 모르고 자동완성으로 뜨는 spring.data.source.maximum-pool-size의 설정 값을 바꿔줬는데 커넥션 풀의 개수가 바뀌질 않아서 몇 시간 동안 고생했던 기억이 납니다.
spring.datasource.slave.maximum-pool-size=(원하는 사이즈)
애플리케이션 단에서 커넥션 풀 크기를 조정해줬다면, 사용할 DB가 커넥션 풀 크기 만큼의 커넥션을 받아서 처리할 수 있도록 DB 서버의 my.cnf 파일 내의 max_connections 값을 조정해줘야 합니다. 다만, 그 기본값이 300이기 때문에 정말 커넥션이 많이 필요한 경우를 제외하고는 왠만해서는 수정할 필요가 없을 것입니다.
참고)
다른 부분에도 항상 적용되는 말이지만 커넥션도 마찬가지로 무조건 많다고 해서 좋은 것이 아닙니다. 커넥션 풀 크기 또한 메모리의 크기에 비례하므로 메모리 사용량이 문제가 될 수 있습니다. 그리고 커넥션의 사용 개수는 DB 서버에서는 Foreground Thread의 생성개수와 같기 때문에 지나치게 많은 쓰레드로 인해 부하가 발생할 수 있습니다. 마지막으로 커넥션을 사용하는 주체는 WAS 서버의 쓰레드이기 때문에, WAS 서버의 쓰레드 개수가 적다면 이를 충분히 사용할 수 없습니다. 그렇다고 쓰레드 개수를 늘리자면 커넥션과 마찬가지로 메모리 사용량과 Context Switching 시 발생하는 부하로 성능에 저하가 생길 수 있습니다.
실제로 https://www.youtube.com/watch?v=xNDnVOCdvQ0 영상을 살펴보면 커넥션 개수를 줄임으로써 오히려 성능이 향상되는 모습을 볼 수 있습니다. 또한 HikariCP 깃허브 페이지를 보면 적정 pool size를 구하는 공식으로 'connections = (core_count * 2) + effective_spindle_count'에 대해서 언급하고 있습니다. 여기서 core count는 CPU 코어의 개수를, 그리고 effective spindle count에서 spindle은 각 HDD 당 하나 씩 있으므로, 넓은 의미에서 하드 디스크의 개수를 의미합니다.
공식을 활용해서 현재 Hello-World 서버의 적정 커넥션 개수를 구해보면 (2 * 2) + 1, 즉 5개가 산출이 됩니다. 하지만 기본 값이 10개임에도 커넥션 부족 문제 가능성이 제기되었기에, 제대로 된 커넥션 풀의 크기를 구하기 위해서는 크기를 늘려가면서 실제 성능 테스트를 진행해보는 방법밖에 없는 듯 합니다. 그리고 위의 공식은 초기 값을 설정할 때나 커넥션의 경우는 다다익선이 아니라는 사실을 깨우치는데 참고하면 되겠습니다.
2차 테스트 후 결과

커넥션 풀 크기를 20개 정도로 조정해주고 다시 테스트를 수행해보았습니다. TPS는 큰 변화가 없어서 그대로 두고, 세부사항만 pinpoint를 통해 살펴보았는데요. 이제는 커넥션 관련 문제는 사라졌지만 로그인을 수행하는 메소드 자체에서 꽤나 많은 지체 시간이 발생했음을 알 수 있었습니다.
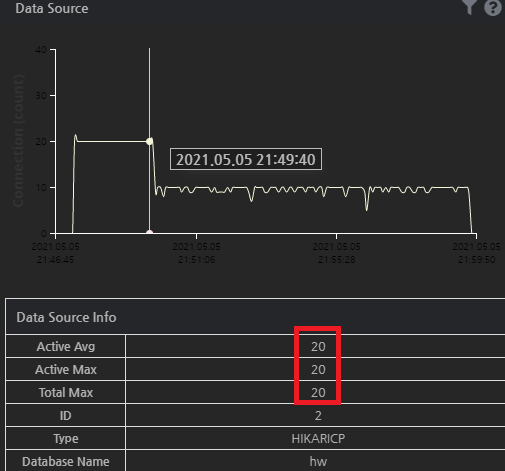
실제로 Datasource 지표를 봐보니 커넥션 사용량도 처음에만 max-size인 20개가 모두 사용되었고, 이후에는 그 절반 정도만 사용되고 있었다는 점을 찾아낼 수 있었습니다. 이로 미루어보아 문제를 일으키고 있던 원인은 커넥션 풀의 크기가 아니었음을 짐작해볼 수 있습니다. 그렇다면 진짜 원인은 무엇이었을까요? 다음 시간에도 해당 문제에 대한 원인을 찾아가는 과정을 계속 포스팅하도록 하겠습니다.
References
개발자가 반드시 알아야 할 자바 성능튜닝 이야기
실무로 배우는 시스템 성능 최적화
https://brownbears.tistory.com/289
https://woowabros.github.io/experience/2020/02/06/hikaricp-avoid-dead-lock.html
프로젝트 링크
https://github.com/f-lab-edu/Hello-World
f-lab-edu/Hello-World
언어교환 상대찾기 서비스. Contribute to f-lab-edu/Hello-World development by creating an account on GitHub.
github.com
'Project > Hello-World (Language Exchange)' 카테고리의 다른 글
| 배포 서버를 대상으로 한 성능테스트 및 성능개선 (4) - 문제의 진짜 원인을 찾아서 (feat. 슬로우 쿼리 & BCrypt) (0) | 2021.06.09 |
|---|---|
| 배포서버 성능테스트 및 성능개선 (2) - 직접 성능테스트를 진행해보고 경과를 모니터링 해봅시다. (0) | 2021.05.31 |
| 배포서버 성능테스트 및 성능개선 (1) - 성능테스트의 필요성을 살펴보고, 필요한 환경을 구성해 봅시다. (0) | 2021.04.27 |
| 대용량 트래픽 속에서도 무거운 DB 조회 연산을 효율적으로 처리하는 방법은 무엇이 있을까요? (2) (0) | 2021.04.13 |
| 대용량 트래픽 속에서도 무거운 DB 조회 연산을 효율적으로 처리하는 방법은 무엇이 있을까요? (1) (0) | 2021.03.29 |



